

Por JULIO ESPINOZA LLANOS
En la industria, detectar defectos en el acero es crucial para evitar pérdidas económicas. Aunque los modelos Deep Learning han avanzado, siguen careciendo de suficientes datos para ser entrenados. Este estudio propone una solución innovadora: usar redes generativas adversarias profundas convolucionales para aumentar datos, superando las limitaciones de disponibilidad de datos al proporcionar un conjunto amplio y diverso de imágenes para entrenar clasificadores. Los resultados muestran la factibilidad de generar imágenes artificiales de defectos en acero idénticas a las reales.
In the steel industry, detecting defects in this metal is crucial to avoid economic losses. Although deep-learning models have progressed, they still lack sufficient data for training. This study proposes an innovative solution: using deep convolutional generative adversarial networks (DCGAN) to augment data, overcoming data availability limitations by providing a large and diverse set of images to train classifiers. The results show the feasibility of generating artificial images of steel defects identical to real ones.
Todos hemos visto últimamente cómo las imágenes “fake” creadas con inteligencia artificial han provocado confusión e incluso problemas políticos o sociales importantes, llevando a pensar que esta tecnología es indeseable. No obstante, si es bien utilizada puede ser beneficioso para la industria, en especial en la producción y control de calidad del acero como se verá a continuación.
En la industria, generalmente se busca obtener modelos que permitan clasificar tipos de defectos, fallas, categorías o incluso discriminar señales de forma automática, ya sea por imágenes, parámetros o sonidos. Para realizar esta labor, los modelos DL necesitan una base de datos importante para su entrenamiento que a menudo es escasa. En este sentido, la disponibilidad limitada de datos representa un desafío significativo en el desarrollo de modelos Deep Learning (DL), sobre todo aquellos referidos a la clasificación de imágenes, especialmente en aplicaciones donde la recopilación manual de datos es costosa y consume excesivo tiempo.
Este estudio se orientó a la industria de la producción de láminas de metal, en la clasificación de imágenes de defectos superficiales en acero, donde crear bases de datos de imágenes con pruebas de laboratorio es costosa y requiere un esfuerzo considerable para entrenar modelos DL.
Redes Generativas Adversarias (GAN´s)
Justo a tiempo, las Generative Adversarial Networks (GAN´s) han experimentado un rápido avance en los últimos años, revolucionando la generación de imágenes realistas y estableciéndose como una técnica prominente en el campo del aprendizaje automático no supervisado. En el artículo pionero de (Goodfellow, 2014) titulado “Generative Adversarial Nets”, se introdujo la arquitectura básica de las GAN´s proponiendo un enfoque novedoso en el que dos redes neuronales, un generador y un discriminador, se entrenan de forma adversaria. El generador aprende a sintetizar muestras realistas, mientras que el discriminador se entrena para distinguir entre muestras reales y generadas. A través de este juego adversario, las GANs logran generar imágenes que se asemejan a las reales a partir de ruido.
Su principio de funcionamiento está relacionado con la idea de que un generador tendrá un buen desempeño si no se puede discriminar si la imagen generada es falsa o verdadera, lo que en términos estadísticos se define como si los datasets tuvieran una misma distribución. En fin, se intenta engañar al discriminador con el objetivo de mejorar la capa generadora a través de la retropropagación de pérdidas (loss) generando un problema minimax con la siguiente función objetivo:
Lo que intenta decir esta función es que se buscan objetivos simultáneos tanto para el discriminador como el generador de la siguiente forma:
O En el Discriminador: La función maximiza cuando al discriminador D se le entrega una imagen real, es decir, D(X) = 1 y a la vez cuando se le entrega al discriminador una imagen generada a partir de ruido G(Z), es decir D(G(Z)) = 0 (fake).
O En el Generador: La función minimiza cuando al discriminador se le entrega una imagen generada G(Z), es decir D(G(Z)) =1.
Ejemplos claros de aplicación de esta técnica fueron el caso de la famosa imagen del Papa vistiendo una chaqueta blanca confundiendo a todos sus seguidores, como también imágenes de caras de personas que realmente no existen o incluso aplicaciones en la transferencia de estilos artísticos, donde se transfieren las características predominantes del estilo artístico de un pintor a una imagen real cualquiera (Transfer Style GAN). En efecto, el producto de estos modelos es solo una sintetización de imágenes creadas por generalización de un modelo GAN.
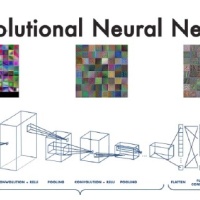
DCGAN: Deep Convolutional Generative Adversarial Networks
Un año después de la aparición de las GAN´s, aparece el artículo de (Radford & Metz, 2015) en el que presentaron el artículo “Unsupervised representation learning with deep convolutional generative adversarial networks”, introduciendo una mejora clave a estos modelos mediante la utilización de redes neuronales convolucionales profundas, conocidas como Deep Convolutional Generative Adversarial Networks (DCGAN). Estas redes permiten generar imágenes de mayor calidad y resolución al aprender representaciones más abstractas y complejas de los datos. No vale la pena entrar en mayor detalle a esto. De forma general, este modelo trabaja igual a un modelo GAN, sin embargo, la parte generadora de éste se encuentra compuesto por capas convolucionales transpuestas que permiten hacer upsampling (expansiones de imágenes) para aumentar su resolución y capas de normalización que permiten normalizar las salidas del generador, estabilizando y acelerando el entrenamiento, lo que en consecuencia genera mayor calidad de las imágenes. En cuanto al componente discriminador del modelo DCGAN, se encuentra compuesto por capas de convolución que son capaces de aplicar filtros barredores en las imágenes para capturar un mapa de características.
Así como las DCGAN han demostrado su eficacia al generar imágenes realistas en muchos dominios, incluyendo el reconocimiento de objetos, la síntesis de caras y la generación de paisajes o arte. Además, su arquitectura ha sentado las bases para desarrollos posteriores en el campo de las GAN´s.
Aplicación de DCGAN en la industria del control de calidad
Ambos artículos mencionados anteriormente han sido claves fundamentales para el desarrollo y la evolución de las GAN´s. Desde su introducción, se han realizado numerosos avances y mejoras en la generación de imágenes, ampliando su aplicabilidad en diversas áreas de investigación y aplicaciones prácticas.
En el presente trabajo se propone una solución innovadora para mejorar el rendimiento de los clasificadores mediante la implementación de una red generativa adversaria profunda convolucional (DCGAN) como técnica de aumento de datos para el dataset de la Universidad Northeastern (NEU) llamado Surface Defect Database. Esta base de datos está formada por 1.800 imágenes en escala de grises de 200x200 pixeles cada una, separadas en 6 tipos de defectos en acero como se muestra en la Ilustración 7. Este banco de imágenes es reducido para usarse en un modelo de clasificación, sobre todo buscando un modelo altamente preciso. Así, la generación de imágenes sintéticas de defectos superficiales en acero, usando el modelo DCGAN, puede superar las limitaciones asociadas con la disponibilidad de datos, al proporcionar un conjunto ampliado y diverso de imágenes para entrenar los clasificadores.
Complementando lo anterior, para efectos prácticos de este estudio, solo se utilizó para el entrenamiento la categoría de tipo scratches (en amarillo). Sin entrar en mayores detalles de implementación, las fases de ejecución fueron las siguientes:
a) Tratamiento de datos inicial: Dado que los datos de texto estaban en formato *.BMP, primero se efectuó la lectura y almacenamiento de éstos con un formato reducido desde 200 a 64 pixeles. Luego, para acelerar el entrenamiento se estandarizaron los valores de las imágenes al ser divididos por 255 (número máximo de color en un pixel).
b) Definición de parámetros del modelo: Se establece el tamaño del espacio latente o ruido, lo cual influye en el detalle de la generación de cada imagen nueva. El número de iteraciones usadas también fue progresivo para ver cómo evoluciona la imagen sintetizada. Y finalmente se establecieron parámetros de aprendizaje como de configuración para cada capa convolucional para dar profundidad al modelo.
Resultados
En la siguiente imagen se puede apreciar el estilo de una muestra real perteneciente al dataset descargado para entrenar al modelo, de manera tal de poder visualizar y comparar diferencias con las imágenes generadas.
Es evidente la evolución de la sintetización desde las primeras iteraciones hasta las últimas 6.000, pasando desde imágenes pixeladas hasta llegar a una imagen casi indistinguible en comparación con las reales. Por otra parte, se asume que 6.000 iteraciones son suficientes para tener buenos resultados sin mayor esfuerzo computacional en un tiempo de 20 minutos.
Conclusiones
Los modelos generativos tienen la capacidad de producir contenido visual increíblemente realista, aunque completamente ficticio, lo que podría ser aprovechado para diseminar información engañosa, noticias falsas o contenido manipulado con repercusiones negativas en lo social y político. No obstante, no todo es adverso, ya que también poseen aplicaciones beneficiosas en la industria. En esta línea, se aplicó un modelo DCGAN como método de ampliación de datos al conjunto de datos de la Universidad Northeastern. Los resultados destacan la casi imperceptible diferencia entre las imágenes generadas y reales, reafirmando la viabilidad de esta técnica para su implementación industrial. Finalmente, la generación de imágenes sintéticas de defectos superficiales en acero utilizando el modelo DCGAN tiene un alto potencial de superar las limitaciones asociadas con la disponibilidad de datos, al proporcionar un conjunto ampliado y diverso de imágenes para entrenar los clasificadores.
Si bien esta técnica se aplicó al ámbito de la generación de datasets para control de calidad de la producción del acero, tiene un alto potencial en diversas áreas, lo cual podría favorecer de sobremanera la forma en que se entrena un modelo de Machine Learning al disponer de una mayor cantidad de datos de entrenamiento.
En la Armada de Chile, podría tener aplicaciones para mejorar modelos de detección de fallas de soldadura, así como en la corrosión, e incluso el control de fuego.
Bibliografía
La corrosión es un problema común en la industria que puede provocar fallas en equipos y estructuras, resultando en pérd...

En un mundo donde las imágenes generadas por inteligencia artificial han causado revuelo y controversia, es fácil olvida...

Versión PDF
Año CXXXX, Volumen 143, Número 1009
Noviembre - Diciembre 2025










ÚLTIMA EDICIÓN
Noviembre - Diciembre 2025
e-ISSN: 0719-4129
ISSN: 0034-8511
Avda. Jorge Montt N° 2400, Las Salinas,
Viña del Mar.
Teléfono: +56 322 848 905
Casilla 220 Correo Central Valparaíso.
Revista indexada en Latindex 2.0
© 2026 Revista de Marina. Todos los derechos reservados.






Inicie sesión con su cuenta de suscriptor para comentar.-