

Por HEDERRA PINTO, FRANCISCO .
El concepto de Network Centric Warfare (NCW), tiene sus orígenes en el año 1996 a partir de los conceptos de System of Systems (Owens, 1996) y el concepto de Dominio Total del Espectro (Full Spectrum Dominance) (Joint Vision 2010, 1996). El concepto de Network Centric Warfare fue propuesto a partir del análisis de casos de estudio de empresas que usaban tecnologías de la información y comunicaciones para mejorar el análisis de la situación. Los autores de este concepto indicaban que la Información es poder y que ha evolucionado de ser un recurso escaso, caro y restringido a un recurso ampliamente disponible, económico y accesible. Su análisis concluía que las organizaciones dominantes en la era de la información logran dominio de sus ecosistemas mediante el desarrollo y explotación de la superioridad de la información, lo cual ya había sido identificado como el estado final deseado del Joint Vision 2010.
Brander et al. (2007) presentaron el uso operacional y táctico de las capacidades habilitadas por el NCW y los desarrollos planificados por organizaciones de defensa de Estados Unidos y Europa. Fuertemente relacionado con lo anterior, Bravo (2010) presenta los distintos procesos de generación de inteligencia, materia fundamental del NCW.
Pugh (1987) publicó en esta revista su visión de lo que serían las aplicaciones de inteligencia artificial en el campo naval mediante una descripción del empleo de los medios en sistemas expertos, los que se encontraban en boga en la época de su publicación. Después de describir su visión en un escenario naval de un país como Estados Unidos, plantea que “En nuestro país es probable que estos avances técnicos tarden un poco en llegar, pero eso no exime nuestra responsabilidad en la preparación de personal para tal suceso.”
En este artículo, se desea mostrar que el tiempo que previó Pugh (1987) ha llegado, presentando la generación de inteligencia en el NCW mediante la fusión de datos y postular las condiciones para materializarla en nuestro país.
NCW plantea que el objetivo final deseado es la superioridad de la información, estado que se alcanza cuando se logra una ventaja competitiva derivada de una posición superior de la información, evaluada en sus aspectos de relevancia, exactitud y oportunidad. Para lograr lo anterior, NCW propone una red integrada de sensores y el valor agregado de la fusión de datos por sobre el paradigma de sensores aislados. Bravo (2010) expone la evolución que ha tenido la inteligencia operacional y táctica y muestra la relación entre datos, información e inteligencia, figura 1, mostrando que esta última es el resultado del procesamiento y análisis de los datos obtenidos de los sensores. Este modelo ha sido profusamente discutido en lo que se ha llamado la fusión de datos e información, para identificar el rol que le corresponde a los operadores y a las máquinas en los distintos niveles de procesos de generación de inteligencia, habiéndose ya asumido que se requiere del análisis de grandes cantidades de información proveniente de diversas fuentes y, consecuentemente, diversos niveles de validez, lo cual un conjunto de operadores no puede lograr en forma oportuna como es requerido, motivando a revisar los conceptos de fusión de datos y las herramientas asociadas.
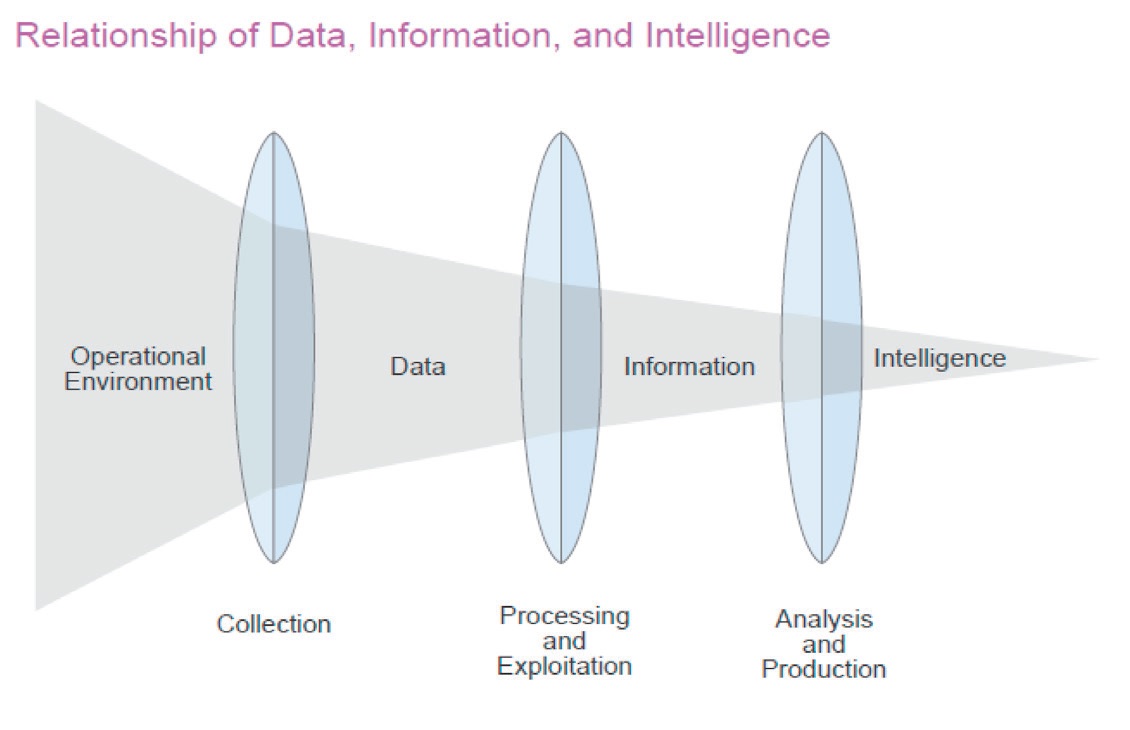
Figura 1. Datos, información e inteligencia (Joint Intelligence, JP 2-2007, pág. 22, http://fas.
org/irp/doddir/dod/jp2_0.pdf).
Como hemos visto, el NCW promueve la información como el factor de superioridad de las fuerzas conjuntas mediante la fusión de datos. Machine Learning es un conjunto de herramientas que permite desarrollar fusión de datos. Ambos conceptos se desarrollan a continuación.
La fusión de datos incluye la teoría, técnicas y herramientas para explotar la sinergia de la información adquirida por distintos sensores (Steinberg, 1999). Es interesante destacar que la introducción de los conceptos de network centric warfare y el de fusión de datos conlleva adicionalmente un importante cambio de paradigma, mostrando una evolución de un sensor-un usuario a la de múltiples sensores múltiples usuarios ya que, además del uso de los datos producto de los sensores, NCW y fusión de datos incluyen aspectos de control remoto de los sensores, asignación de tareas a los mismos y distribución de la información.
Desde su definición, el concepto de fusión de datos evolucionó al concepto de Fusión de Información (FI), para abarcar, entre otros aspectos, la generación de inteligencia con participación del operador y la integración de productos de inteligencia. La clasificación de los procesos de fusión de información, figura 2 (DFIG 2004 Model), definiendo niveles según la complejidad del nivel de toma de decisiones que apoya la información producida y consecuentemente, la complejidad de las herramientas que los producen:
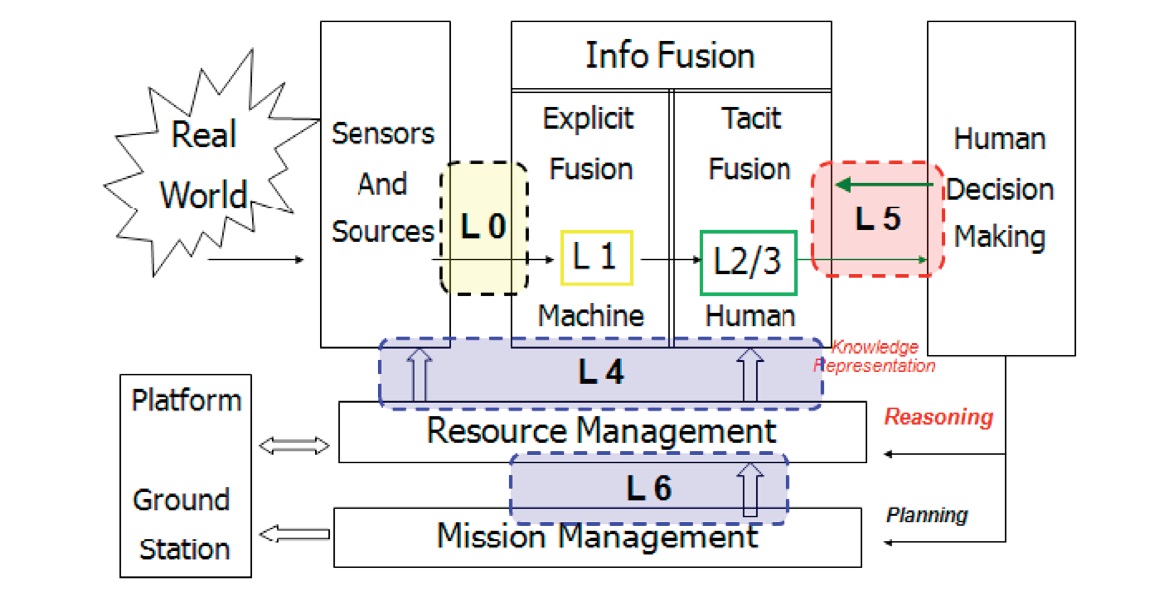
Figura 2. Modelo de fusión de información DFIG 2004. (https://www.researchgate.net/profile/
Erik_Blasch/publication/300791820_One_decade_of_the_Data_Fusion_Information_
Group_DFIG_model/links/570d1abd08ae2b772e42f14c/One-decade-of-the-Data-Fusion-
Information-Group-DFIG-model.pdf)
Los beneficios de la fusión de información de múltiples fuentes incluyen el mejorar la cantidad y validez de los resultados, ya sea por consistencia en el escenario o consistencia en el tiempo. O’Shaughnessy (2000) indica que, en el caso de la construcción del panorama táctico, el uso de múltiples sensores compartidos sobre una red de datalink para formar un panorama táctico común, puede resultar en mejoras en la disponibilidad del panorama de cada plataforma, cobertura y robustez, reduciendo la susceptibilidad a interferencias o decepción del enemigo.
Respecto de las herramientas empleadas en fusión de la información, se han desarrollado un gran número de ellas, estando hoy en el estado del arte aquellas categorizadas como inteligencia artificial y su derivado, machine learning. Lo que hoy conocemos como inteligencia artificial se inicia en 1950 cuando Alan Turin publicó un artículo en el que especulaba respecto de la posibilidad de crear máquinas que pensaran, indicando que era difícil definir el concepto de pensar, pero que ciertamente si una máquina podía mantener una conversación que no pudiese distinguirse de aquella que mantenía un ser humano, era razonable decir que la máquina pensaba. Muchos desarrollos le siguieron, entre los que se destacan las primeras redes neuronales el año 1958 y los sistemas expertos en 1980. Machine learning, por otra parte, son técnicas estadísticas que permite que los computadores aprendan con datos, sin ser expresamente programados (Samuel, 1959).
Las herramientas de machine learning han demostrado su capacidad de generalizar clasificaciones y predicciones hechas por seres humanos en un conjunto reducido de datos, mediante el proceso llamado aprendizaje. Esta capacidad de generalizar es lo que hace tremendamente poderoso al concepto, ya que pueden extender el aprendizaje de casos particulares a casos generales del mismo modo que el ser humano aprende. Las herramientas de machine learning se clasifican de acuerdo al método de aprendizaje, lo cual está fuera del alcance de este artículo, pero básicamente identifican el método que se debe emplear para entrenar la herramienta. La figura 3 (Aplicaciones de machine learning) muestra algunas aplicaciones de machine learning, clasificadas según el método de aprendizaje, sin supervisión, supervisado y reforzado.
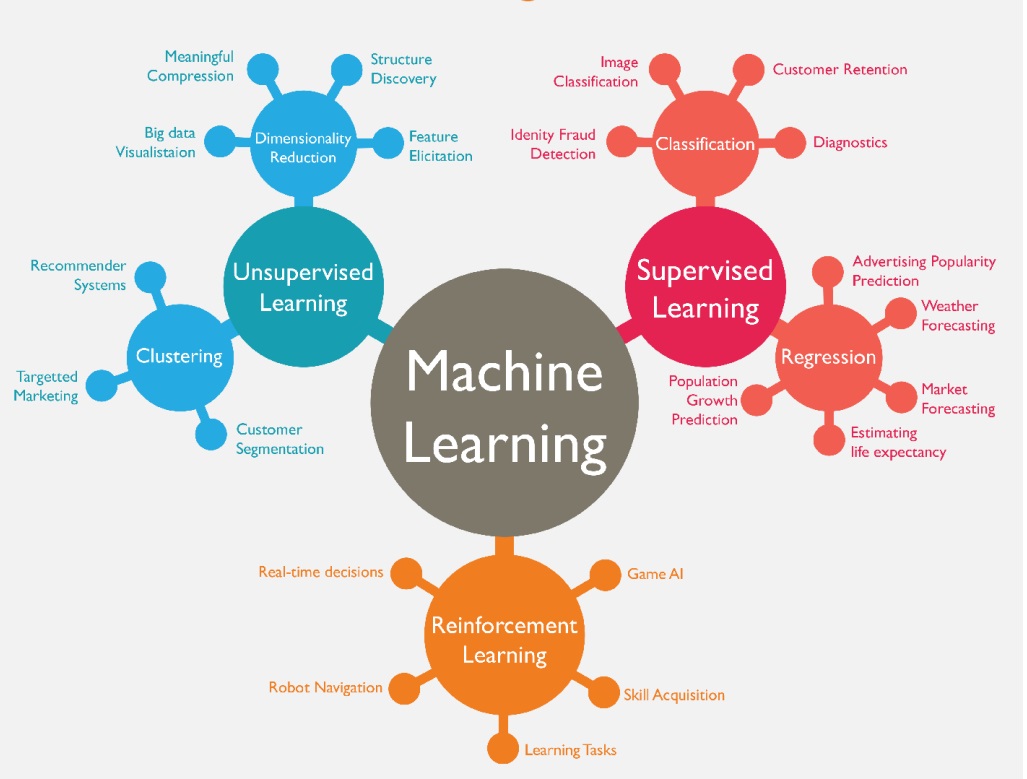
Figura 3. Aplicaciones de machine learning (https://medium.com/marketing-andentrepreneurship/
10-companies-using-machine-learning-in-cool-ways-887c25f913c3).
Cabe mencionar que el concepto deep learning, empleado frecuentemente en la literatura, se refiere a la metodología para entrenar el caso particular de redes neuronales profundas (con muchas capas).
Los tipos de problemas que pueden ser resueltos mediante machine learning se pueden clasificar, en (Aggarwal, 2015):
Las aplicaciones de fusión de información y machine learning en distintas disciplinas han sido numerosas y variadas, por ejemplo, en el área de la industria (análisis de mercado, business intelligence y otros), la defensa (adquisición, traqueo y caracterización de blancos, dominio del espectro), policiales (control de fronteras, control de piratería, aplicación de SISDEF en la identificación de conductas anómalas y análisis de discrepancias en el monitoreo de tráfico marítimo), seguridad (sistemas biométricos, reconocimiento en imágenes), medicina (diagnóstico, imageología y radiología), transporte (vehículos autónomos) y muchos otros de abundante literatura. Más aun, cada vez que observamos que nuestras interacciones con máquinas son aprendidas y generalizadas (buscadores internet, UBER, captcha, y otros), se debe a que en el background hay un algoritmo de machine learning que está aprendiendo con nuestras acciones (IBM Watson, Google Deepmind, etc).
No quisiera abandonar esta sección sin antes indicar algunas consideraciones en este dominio:
Para revisar los beneficios de fusión de información y machine learning, usaré un caso de uso que ha aparecido repetidamente en la prensa y que atañe a la labor marítima de la institución, como son la fiscalización de la pesca no reportada y no regulada, la inmigración ilegal y el tráfico de ilícitos por mar en los océanos. También se ha agregado la creciente demanda por la fiscalización de las áreas y parques marinos protegidos. Las características del problema son:
Debido a las dimensiones y complejidad del problema, esta tarea de análisis puede ser cumplida por un número importante de personas, arriesgando la oportunidad del resultado, o por un analista que trabaje de manera colaborativa con una aplicación de software. Este es un escenario en el que las herramientas de fusión de información y machine learning sin duda aportan valor en la construcción del panorama y ayuda a orientar los esfuerzos. Adicionalmente, la implementación de ellas tendría los siguientes beneficios para el Estado de Chile:
El estado de desarrollo e implementación en los sectores de la industria y la defensa indican que las herramientas de fusión de información y machine learning tienen un estado de madurez que traspasó el área de la investigación y hoy agregan valor en la generación de inteligencia en múltiples dominios, lo que puede reportar beneficios importantes a quienes hagan uso de ellos.
Más aún, el avance de la tecnología, los costos de capacitación del personal en áreas de especialidad y las restricciones de cantidad de personal permiten prever que este tipo de herramientas facilitarán el uso de nuevo equipamiento que se incorpore.
En definitiva, ha llegado el tiempo en que la Armada debe iniciar el desarrollo de las herramientas de NCW, fusión de información y machine learning que le den una posición ventajosa en el ámbito marítimo y el de la defensa, los cuales pueden encontrar sinergias beneficiosas.

Versión PDF
Año CXXXX, Volumen 143, Número 1009
Noviembre - Diciembre 2025










ÚLTIMA EDICIÓN
Noviembre - Diciembre 2025
e-ISSN: 0719-4129
ISSN: 0034-8511
Avda. Jorge Montt N° 2400, Las Salinas,
Viña del Mar.
Teléfono: +56 322 848 905
Casilla 220 Correo Central Valparaíso.
Revista indexada en Latindex 2.0
© 2026 Revista de Marina. Todos los derechos reservados.






Inicie sesión con su cuenta de suscriptor para comentar.-